arnjen.com Indexing Collapse: From 250 Indexed Pages to 1

In the previous posts about arnjen.com, I documented the indexing journey as it was happening.
At first, the site was getting some small traction, but most of the pages were still not indexed. Then, in the second update, things looked much better: almost everything had entered Google’s index.
Now, this is the final update in that sequence.
The result is not what I expected.
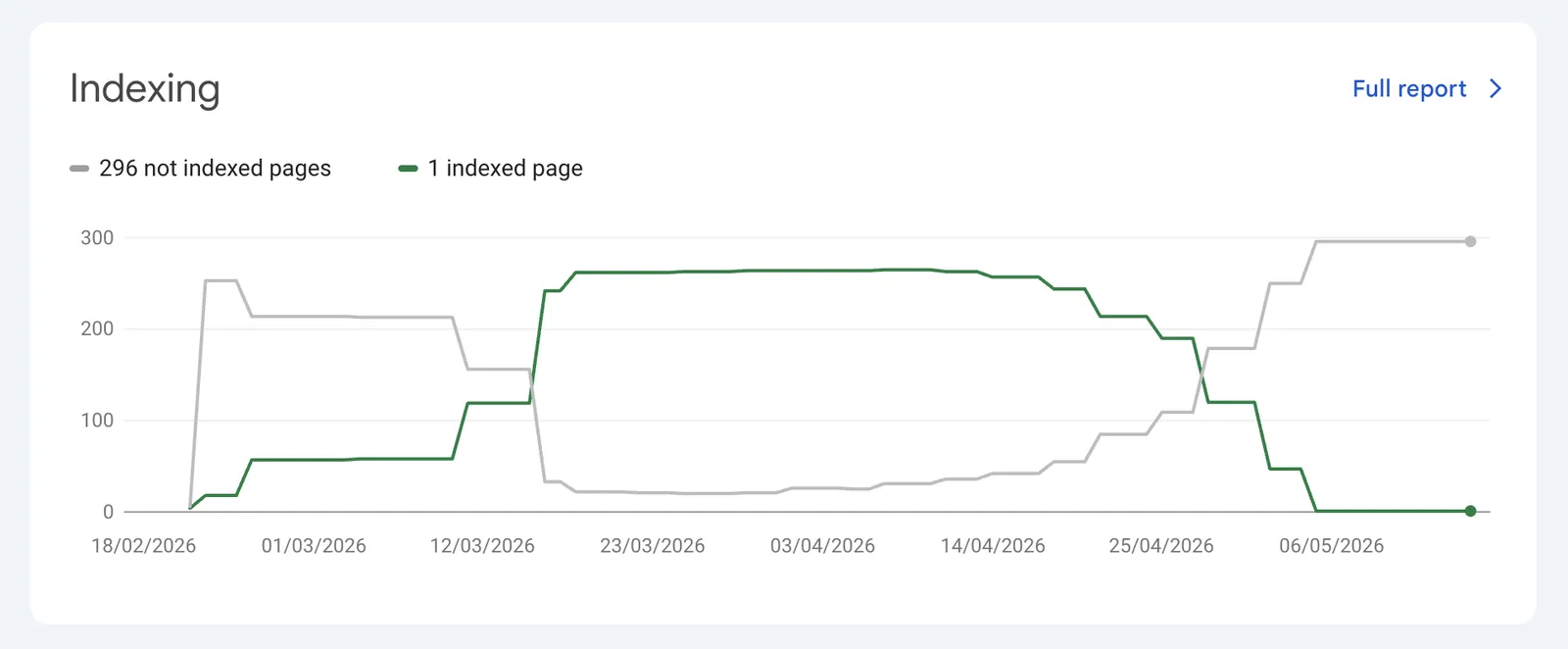
After arnjen.com reached roughly 250 indexed pages, Google started removing pages from the index in batches. Around one and a half months later, almost the entire site had disappeared from Google’s index.
At the time of writing, Google Search Console shows:
- 296 not indexed pages
- 1 indexed page
That one indexed page is the homepage.
So this post is about the full indexing collapse: how arnjen.com went from almost fully indexed to almost completely removed from Google’s index.
Previous parts in this series:
- Part 1: Small traction, but not much indexed yet
- Part 2: Almost everything got indexed
- Part 3: This post - from 250 indexed pages to 1
The site was not ignored by Google
The most important thing to understand is that arnjen.com was not simply ignored by Google.
This was not a case where Google never discovered the pages.
The site was crawled.
The pages were discovered.
Many of them were indexed.
The indexed page count climbed to around 250 pages.
That matters because it changes the diagnosis.
If a site never gets indexed, the first questions are usually technical:
- Can Google crawl the pages?
- Are the pages blocked by robots.txt?
- Is there a noindex tag?
- Are the pages orphaned?
- Is the sitemap working?
- Are internal links discoverable?
But that is not the main pattern here.
In this case, Google did index the site first. The problem happened later.
The pages entered the index, stayed there for a short period, and then started dropping out in batches.
That makes this more of an index retention problem than a basic discovery problem.
The current status: Crawled - currently not indexed
The removed URLs are now showing under:
Crawled - currently not indexed
This is the key detail.
It means Google has already crawled the pages. The URLs are not unknown to Google. They are not simply waiting to be discovered. Google has seen them, processed them, and then chosen not to include them in the index.
That makes the situation more specific.
The issue is probably not:
Google cannot find the pages.
The better question is:
Why does Google not want to keep these pages indexed?
For arnjen.com, this is what makes the case interesting. The pages were not rejected immediately. They were indexed first, then removed later after Google had more time to evaluate the site.
That suggests Google initially allowed the content into the index, but later reassessed the pages and decided that most of them were not worth keeping.
The timeline: from indexed to de-indexed in batches
The timeline looks roughly like this:
- arnjen.com launched with many pages.
- Google discovered the site.
- At first, only a limited number of pages were indexed.
- More pages gradually started entering the index.
- The site reached roughly 250 indexed pages.
- Indexation stayed high for a short period.
- Google then started removing pages in batches.
- The indexed count dropped sharply.
- Eventually, only one page remained indexed.
The important detail is the batch pattern.
The de-indexing did not happen all at once. It happened step by step. That suggests Google was processing groups of URLs over time, possibly by page type, template, topic cluster, or content similarity.
This kind of decline feels very different from a single technical mistake.
For example, if I had accidentally added a sitewide noindex tag, the drop would probably be more sudden and more obviously technical. But here, the pages were moved into Crawled - currently not indexed, which points more toward Google making an index selection decision.
Google crawled the pages, but decided not to keep them indexed.
Search performance disappeared with the indexing collapse
The performance data also shows the effect clearly.
During the selected three-month period, arnjen.com recorded:
- 72 total clicks
- 68.5K total impressions
- 0.1% average CTR
- 6.9 average position
The site did get visibility.
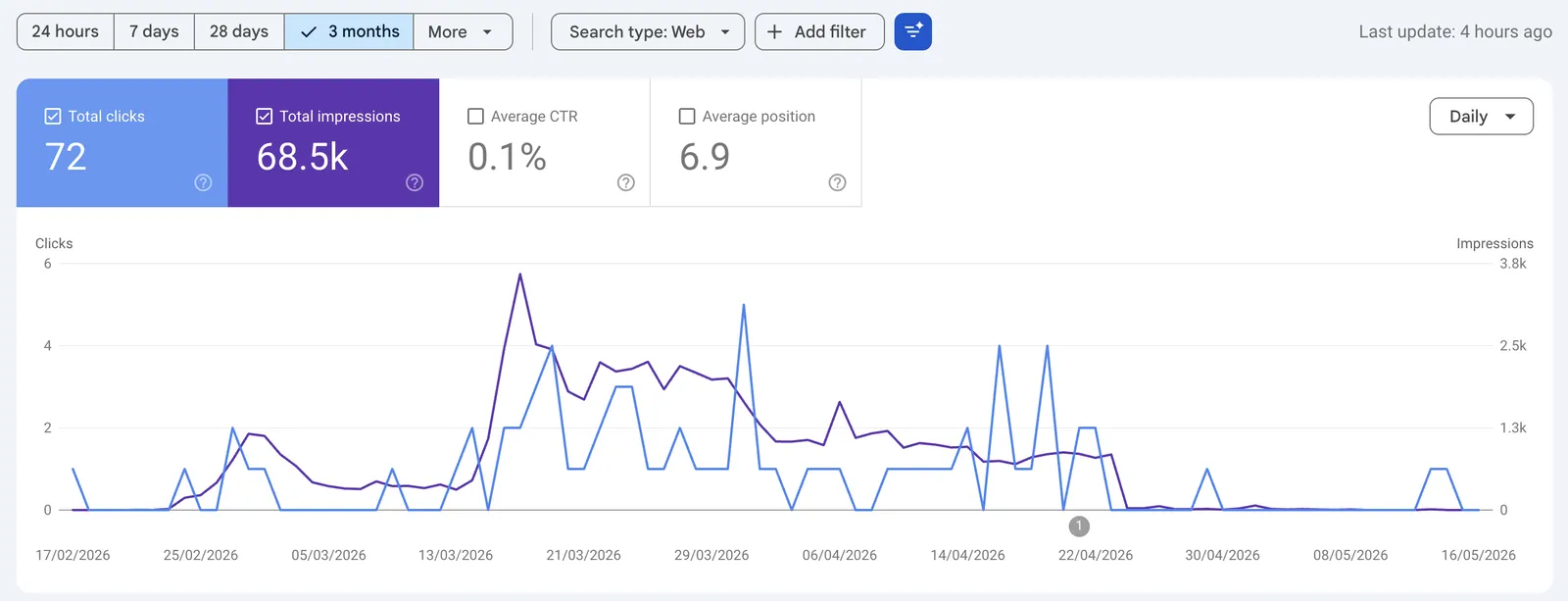
It was appearing in search results. It received impressions. It even received some clicks, although the CTR was very low.
But once the indexation dropped, impressions collapsed as well.
This is expected, but it is still important to show.
When pages are removed from the index, they cannot rank. If they cannot rank, they cannot generate impressions. If they cannot generate impressions, they cannot bring organic traffic.
So the performance drop was not just a ranking decline. It was more fundamental than that.
The pages were no longer eligible to appear because Google removed them from the index.
Why “Crawled - currently not indexed” matters
The status Crawled - currently not indexed is one of the most frustrating statuses in Google Search Console.
It tells you that Google has done the first part of the job: crawling.
But it has not done the second part: indexing.
That means the problem is not necessarily access. It is selection.
Google is effectively saying:
I know this URL exists. I crawled it. But I am not indexing it right now.
For a small number of pages, that can happen naturally. Not every URL on a website deserves to be indexed.
But when almost the entire site moves into this category, it becomes a much bigger signal.
For arnjen.com, the fact that only the homepage remains indexed suggests that Google currently does not trust, value, or prioritize most of the other pages enough to keep them in the index.
That does not automatically prove that every page is bad. But it does mean Google is not convinced that those pages deserve to stay indexed.
What likely caused the drop?
I cannot say with 100% certainty what caused the collapse without inspecting every URL individually, but the pattern gives some strong clues.
Because the pages were crawled and previously indexed, I would not start by assuming this is a simple crawling issue.
The more likely causes are related to quality, duplication, usefulness, and index-worthiness.
Possible causes include:
1. The pages may be too similar to each other
If many pages use the same structure, same wording, same format, or only slightly different targeting, Google may decide they are not distinct enough to index individually.
This is especially common with programmatic SEO and AI-assisted content sites.
A page can technically be unique, but still feel repetitive at scale.
If Google sees hundreds of pages that follow the same pattern and do not add much new information, it may crawl them but choose not to index them.
2. The pages may not provide enough unique value
Google does not need to index every page it crawls.
If a page does not offer something meaningfully useful compared with existing results, Google may leave it out of the index.
For arnjen.com, this is one of the main things to investigate.
The question is not only:
Is the content original?
The better question is:
Is the page useful enough that Google would want to show it instead of what is already ranking?
That is a much harder standard.
3. The site may have scaled faster than its authority supported
A newer or weaker domain may struggle to keep hundreds of pages indexed, especially if those pages are not strongly differentiated.
Google may initially index a large batch of URLs, then later reduce the index footprint if the site does not earn enough engagement, links, trust, or topical authority.
This does not mean a new site cannot have many indexed pages. But the more pages a site publishes, the stronger the quality and internal structure need to be.
4. The internal linking may not be strong enough
If many pages are only lightly linked, buried deep, or not clearly connected to important sections of the site, Google may treat them as low-priority.
Internal links help Google understand which pages matter.
If the site has hundreds of pages but weak internal linking, Google may crawl them but decide not to keep them indexed.
For arnjen.com, I would review whether the removed pages have strong internal links from relevant pages, category pages, hub pages, and the homepage.
5. The content may be too template-driven
Template-driven pages can work, but only if the unique content on each page is strong enough.
If the template dominates and the unique section is thin, Google may see the pages as near-duplicates or low-value variations.
This is one of the most likely risks when publishing many pages quickly.
A page needs more than a unique title and a few changed terms. It needs a clear reason to exist as a separate indexed URL.
Why this is not just a “request indexing again” problem
When pages are in Crawled - currently not indexed, it can be tempting to simply request indexing again in Google Search Console.
But that is unlikely to fix the core issue.
Google has already crawled the pages.
The problem is not that Google needs to be reminded that the pages exist. The problem is that Google has not decided to keep them indexed.
Requesting indexing may temporarily push a URL back into review, but if the underlying page quality and site signals do not improve, the same thing can happen again.
For arnjen.com, the goal should not simply be to force the pages back into the index.
The goal should be to make the pages more index-worthy.
That means improving the pages before asking Google to reconsider them.
What I would do next
The next step is to investigate the affected URLs in groups.
I would not look at one random URL and try to draw a conclusion from it. Instead, I would group the removed URLs by page type and look for patterns.
The main things I would check are:
1. Compare indexed vs. non-indexed pages
Since the homepage is still indexed, I would compare it with the removed pages.
What does the homepage have that the other pages do not?
It may have stronger internal links, more brand signals, clearer purpose, better uniqueness, or simply more importance in the site structure.
Then I would compare the removed pages against each other.
Are they all using the same layout?
Are they targeting similar keywords?
Are they thin?
Are they generated from the same source pattern?
Do they repeat the same explanations?
The goal is to find what Google may be rejecting at scale.
2. Inspect several URLs manually
I would take a sample of removed URLs and inspect them in Google Search Console’s URL Inspection Tool.
For each one, I would check:
- Last crawl date
- Google-selected canonical
- User-declared canonical
- Whether the page is crawlable
- Whether indexing is allowed
- Whether the page is mobile usable
- Whether the rendered page matches what users see
- Whether Google reports any obvious indexing issue
This helps separate quality problems from technical problems.
Even though the current status suggests an index selection issue, technical problems should still be ruled out.
3. Strengthen internal linking
If the pages are important, they should be linked like important pages.
I would create stronger hub pages, category pages, and contextual internal links between related pages.
Each page should not feel isolated.
Google should be able to understand where the page fits in the site and why it matters.
4. Improve uniqueness page by page
The biggest improvement should probably be on the page level.
Each page needs to answer:
Why should this URL exist as its own page?
That means adding more unique information, better examples, clearer intent matching, and stronger differentiation from similar pages.
If multiple pages are targeting similar queries with similar content, they may need to be merged, rewritten, or removed.
5. Reduce weak pages
Sometimes the solution is not to improve all pages.
Sometimes the better move is to reduce the number of pages and only keep the strongest ones.
If arnjen.com has hundreds of pages but many are thin or repetitive, it may be better to consolidate the site around fewer, better pages.
A smaller site with stronger pages is often easier to get indexed than a larger site with many weak URLs.
What this teaches about SEO
This case shows an important SEO lesson:
Getting indexed is not the same as staying indexed.
A page can pass through multiple stages:
- Discovered
- Crawled
- Indexed
- Tested in search
- Reassessed
- Kept or removed
Many people stop paying attention after step three.
But Google can come back later and change its mind.
That appears to be what happened with arnjen.com. Google discovered the site, crawled the pages, indexed many of them, and then later removed almost all of them.
This is why index retention matters.
For sites using AI content, programmatic SEO, or scaled publishing, the main challenge is not only producing pages. The main challenge is producing pages that Google continues to believe are worth indexing.
The main lesson from arnjen.com
The main lesson from this case is simple:
Google may index a site initially, but that does not mean the pages have earned a permanent place in the index.
arnjen.com went from limited indexation, to almost fully indexed, to almost completely de-indexed.
The final state is severe:
- Around 250 pages were indexed at the peak.
- The site later dropped to only 1 indexed page.
- 296 pages are now not indexed.
- The removed pages are in Crawled - currently not indexed.
- Search impressions collapsed after the pages left the index.
That makes this a clear index retention failure.
The pages were not invisible to Google. They were crawled. Many were indexed. But Google later decided not to keep them.
Conclusion
This is the third and final post in the arnjen.com indexing case study.
The first post showed the early stage, where the site had some small traction but not much indexation.
The second post showed the positive stage, where almost everything became indexed.
This final post shows the reversal.
arnjen.com reached roughly 250 indexed pages, then Google removed the pages in batches over the following weeks. Now, only the homepage remains indexed, while the rest of the pages sit in Crawled - currently not indexed.
The next step is not simply to request indexing again.
The real task is to understand why Google crawled the pages but decided not to index them anymore.
That means improving page uniqueness, reducing repetition, strengthening internal links, reviewing canonical signals, and making each page clearly valuable enough to deserve a place in Google’s index.
For arnjen.com, the case study is a strong reminder that indexing is not binary.
A page is not safe just because it gets indexed once.
Google can crawl it, index it, test it, reassess it, and remove it later.
And that is exactly what happened here.